Step 5: Train the model: This code initiates the training of the neural network model using the training data (X_train and y_train) for 20 epochs, with a batch size of 32. The validation data (X_test and y_test) is used to evaluate the model’s performance during training:
Train the model
model.fit(X_train, y_train, epochs=20, batch_size=32, \
validation_data=(X_test, y_test))
Step 6: Test the accuracy of the model: After training completion, it calculates the test accuracy of the model on the separate test set and prints the accuracy score, providing insights into the model’s effectiveness in classifying audio data:
Test the accuracy of model
test_accuracy=model.evaluate(X_test,y_test,verbose=0)
print(test_accuracy[1])
Here is the output:
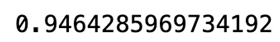
Figure 11.6 – Accuracy of the model
Step 7: Save the trained model:
Save the model
model.save(‘audio_classification_model.h5’)
Step 8: Test the new audio file: Let’s classify the new audio file and label it using this saved model:
Load the saved model
model = load_model(‘audio_classification_model.h5’)
Define the target shape for input spectrograms
target_shape = (128, 128)
Define your class labels
classes = [‘cat’, ‘dog’]
Function to preprocess and classify an audio file
def test_audio(file_path, model):
Load and preprocess the audio file
audio_data, sample_rate = librosa.load(file_path, sr=None)
mel_spectrogram = librosa.feature.melspectrogram( \
y=audio_data, sr=sample_rate)
mel_spectrogram = resize(np.expand_dims(mel_spectrogram, \
axis=-1), target_shape)
mel_spectrogram = tf.reshape(mel_spectrogram, (1,) + target_shape + (1,))
This code defines a function, test_audio, to preprocess and classify an audio file. It loads and preprocesses the audio data from the specified file path using Librosa, generating a mel spectrogram. The spectrogram is then resized and reshaped to match the input dimensions expected by the model. This function is designed to prepare audio data for classification using a neural network model, providing a streamlined way to apply the trained model to new audio files for prediction.
Now, let’s make predictions. In this code segment, predictions are made using the trained neural network model on a specific audio file (./cat-meow-14536.mp3). The test_audio function is employed to preprocess the audio file and obtain class probabilities and the predicted class index. The model.predict method generates predictions, and the class probabilities are extracted from the result. The predicted class index is determined by identifying the class with the highest probability. This process demonstrates how the trained model can be utilized to classify new audio data, providing insights into the content of the tested audio file:
Make predictions
predictions = model.predict(mel_spectrogram)
Get the class probabilities
class_probabilities = predictions[0]
Get the predicted class index
predicted_class_index = np.argmax(class_probabilities)
return class_probabilities, predicted_class_index
Test an audio filetest_audio_file = ‘../Ch10/cat-meow-14536.mp3’
class_probabilities, predicted_class_index = test_audio( \
test_audio_file, model)
The following code snippet iterates through all the classes in the model and prints the predicted probabilities for each class, based on the audio file classification. For each class, it displays the class label and its corresponding probability, providing a comprehensive view of the model’s confidence in assigning the audio file to each specific category:
Display results for all classes
for i, class_label in enumerate(classes):
probability = class_probabilities[i]
print(f’Class: {class_label}, Probability: {probability:.4f}’)
The following code calculates and reveals the predicted class and accuracy of the audio file classification. It identifies the predicted class using the index with the highest probability, retrieves the corresponding class label and accuracy from the results, and then prints the predicted class along with its associated accuracy. This provides a concise summary of the model’s prediction for the given audio file and the confidence level associated with the classification. Calculate and display the predicted class and accuracy:
predicted_class = classes[predicted_class_index]
accuracy = class_probabilities[predicted_class_index]
print(f’The audio is labeled Spectrogram Visualization
as: {predicted_class}’)
print(f’Accuracy: {accuracy:.4f}’)
This is the output we get:

Figure 11.7 – Output showing probabilities and accuracy of the model
We have seen how to transcribe audio data using machine learning. Now, let’s see how to do audio data augmentation and train a model with augmented data. Finally, we will see and compare the accuracy with and without augmented data.