Branching strategies and the GitOps workflow
GitOps requires at least two kinds of Git repositories to function: the application repository, which is from where your builds are triggered, and the environment repository, which contains all of the infrastructure and configuration as code (CaC). All deployments are driven from the environment repository, and the changes to the code repository drive the deployments. GitOps follows two primary kinds of deployment models: the push model and the pull model. Let’s discuss each of them.
The push model
The push model pushes any changes that occur within your Git repository to the environment. The following diagram explains this process in detail:
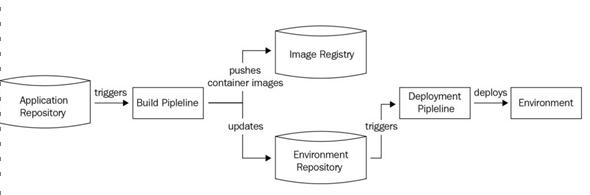
Figure 2.10 – The push model
The push model is inherently unaware of the existing configuration and reacts only to changes made to your Git repositories. Therefore, you will need to set up some form of monitoring to understand whether there are any deviations. Additionally, the push model needs to store all environment credentials within the tools. This is because it interacts with theenvironment and has to manage the deployments. Typically, we use Jenkins, CircleCI, or Travis CI to implement the push model. While the push model is not recommended, it becomes inevitable in cloud provisioning with Terraform, or config management with Ansible, as they are both push-based models. Now, let’s take a closer look at the pull model.
The pull model
The pull model is an agent-based deployment model (also known as an operator-based deployment model). An agent (or operator ) within your environment monitors the Git repository for changesand applies them as and when needed. The operator constantly compares the existing configuration with the configuration in the environment repository and applies changes if required. The following diagram shows this process in detail:
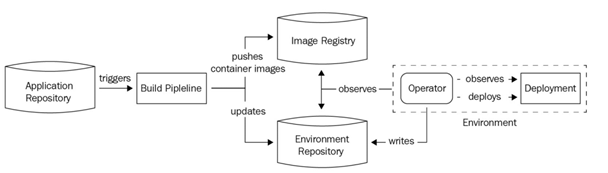
Figure 2.11 – The pull model
The advantage of the pull model is that it monitors and reacts to environment changes alongside repository changes. This ensures that any changes that do not match the Git repository are reverted from the environment. It also alerts the operations team about anything it could not fix using mail notifications, ticketing tools, or Slack notifications. Because the operator lives within the same environment where the code is deployed, we do not need to store credentials within the tools. Instead, they live securely within the environment. You can also live without storing any credentials at all with tools such as Kubernetes, where you can employ role-based access control (RBAC) and service accounts for the operator managing the environment.
Tip
When choosing a GitOps model, the best practice is to check whether you can implement a pull-based model instead of a push- based model. Implement a push-based model only if a pull-based model is not possible. It is also a good idea to implement polling in the push-based model by scheduling something, such as a cron job, that will run the push periodically to ensure there is no configuration drift.
We cannot solely live with one model or the other, so most organizations employ a hybrid model to run GitOps. This hybrid model combines push and pull models and focuses on using the pull model.
It uses the push model when it cannot use the pull model. Now, let’s understand how to structure our Git repository so that it can implement GitOps.